
Atelier 1: HDFS
- Créer un dossier et copier dedans les ressources de TP(fichier texte, csv, …)
- Clic droit sur le nom de la VM
 /
/
 Configuration / Général / Avancé / Presse-papier
partagé : Bidirectionnel
Configuration / Général / Avancé / Presse-papier
partagé : Bidirectionnel - Clic sur
 / Clic sur
/ Clic sur
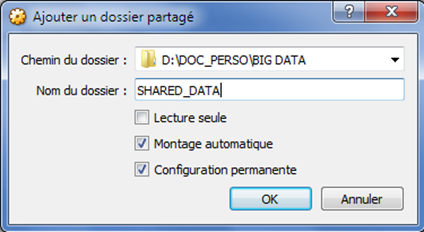
 / Choisir un dossier, donner lui
un nom de partage et cocher les deux cases Montage automatique et Configuration permanente
/ Choisir un dossier, donner lui
un nom de partage et cocher les deux cases Montage automatique et Configuration permanente
- Démarrer votre VM et lancer un terminal
- Modifier le clavier en azerty: setxkbmap fr
- Taper la commande: mkdir shared_data
- Taper la commande: sudo mount -t vboxsf shared_data shared_data
- Un raccourci vers le dossier partagé est ajouté sur le bureau de la VM
- Télécharger et installer un client SSH (PuTTY, Secure Shell Client, BitVise SSH, ...)
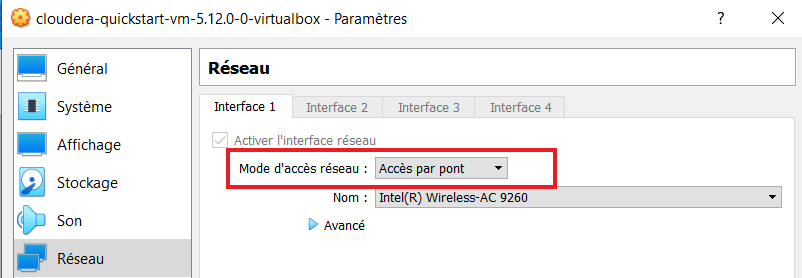
- Si vous utilisez VirtualBox: Dans la fenêtre de configuration de la VM, modifier le mode d'accès réseau: Accès par pont
- Dans un terminal de votre VM, lancer la commande: ip addr
- Noter l'adresse IP de votre VM, par exemple 192.168.1.15
- Lancer un client SSH (PuTTY, Secure Shell Client, BitVise SSH, ...)
- Se connecter en utilisant l'adresse IP de votre VM. Le nom d'utilisateur et le mot de passe sont respectivement: root , cloudera
- Vous êtes maintenant connecté au cluster Hadoop
- Dans un terminal, afficher le contenu du fichier /etc/hadoop/conf/core-site.xml
- Quel est l'URL du processus serveur NameNode de HDFS ainsi que le port?
- Est-ce que c'est équivalent à localhost ? Pourquoi ?
- Quel est la valeur du facteur de réplication?
4. Vérification de l'état des services:
- Utiliser la commande service nomservice status pour vérifier l'état des services suivants:
- hadoop-hdfs-namenode
- hadoop-hdfs-secondarynamenode
- hadoop-hdfs-datanode
- hadoop-hdfs-journalnode
- hadoop-yarn-resourcemanager
- hadoop-yarn-nodemanager
- Utiliser l'outil jps pour lister les processus Java en cours d'exécution:
$ sudo jps -l
Noter les différents processus relatifs aux cinq services cités auparavant:
org.apache.hadoop.hdfs.server.namenode.NameNode
org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
org.apache.hadoop.hdfs.server.datanode.DataNode
org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
org.apache.hadoop.yarn.server.nodemanager.NodeManager
org.apache.hadoop.hdfs.qjournal.server.JournalNode
- On doit avoir les fichiers FL_insurance.csv et purchases.txt dans un dossier de votre VM.
- Lister le contenu de la racine HDFS
- Créer un dossier HDFS tp dans /user
- Copier le fichier local FL_insurance.csv vers le dossier HDFS /user/tp
- Afficher le contenu du dossier HDFS /user/tp
- Afficher les dernières lignes du fichier FL_insurance.csv dans HDFS
- Récupérer la taille d'un block HDFS: hdfs getconf -confKey dfs.blocksize
- Récupérer le facteur de réplication: hdfs getconf -confKey dfs.replicatio
- Copier le fichier local purchases.txt vers le dossier HDFS /user/tp
- Utiliser la commande hdfs fsck pour afficher un rapport détaillé sur le fichier purchases.txt dans HDFS.
-
Quel est le nombre de blocs?
- Quelle est la taille moyenne de chacun?
- Quel est le facteur de réplication (Default replication factor)?
- Quel est le nombre de data-nodes contenant les blocs des fichiers du dossier HDFS?
- Quel est le nombre de blocs corrompus?
- Modifier le facteur de réplication, valeur 2, du fichier purchases.txt dans HDFS:
$ hadoop fs -setrep -w 2 /user/tp/purchases.txt
ou $ hdfs dfs -setrep -w 2 /user/tp/purchases.txt

N.B: Cette commande prendra beaucoup de temps à s'exécuter si le fichier est volumineux
- Utiliser la commande hdfs fsck pour afficher un rapport détaillé sur le dossier HDFS /user/tp
- Quel est le nombre de blocs?
- Quel est le facteur de réplication (Default replication factor) ?